
네이버에서 사이트 웹문서를 수집 및 색인 노출 하는 것은 2번의 과정을 거친다고 생각하셔야 합니다.
여기서 크롤러가 수집하는 것과 그렇지 않고 rss를 수집 하는 것 2가지가 있다고 생각하시면 편합니다.
네이버의 수집편의를 위한 그들만의 방식일 것입니다.
rss를 수집하면 어떠한 글이 발행이 되었는지 아주 빠르게 수집할 수 있습니다. 그래서 네이버는 우선 rss 를 그대로 긁어서 일단 수집 및 노출을 합니다.
그리고 나름 임시로 수집 노출하고 있는 문서들이 rss 정보와 다른 내용으로 출력되고 있을 가능성이 있기 때문에 이 문서들을 파싱을 하는 봇이 직접 방문해서 봇이 실제 보여지는 모습으로 다시 수집해서 해당 정보로 교체합니다.
(RSS정보나 메타정보를 속여서 발행해도 무소용입니다.)
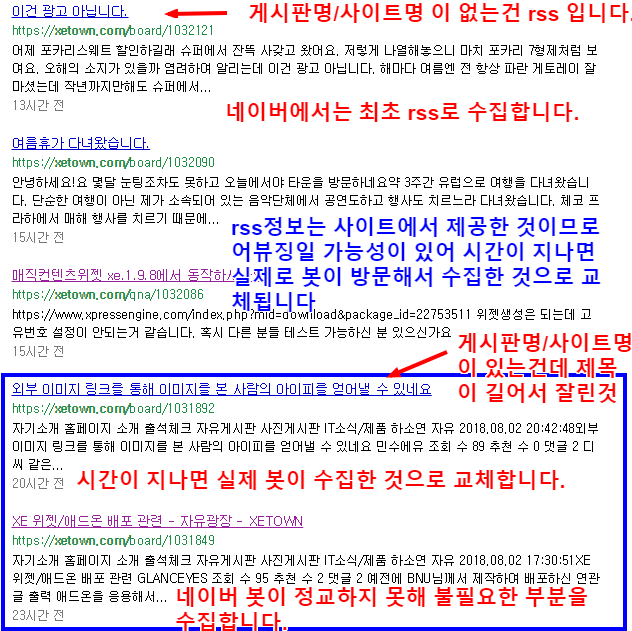
어떠한 이유로 특정 사이트들은 실제 파싱을 하지 못하고 rss 수집한 정보 그대로 계속 머무는 경우도 있습니다.
*문서제목 - 게시판명 - 사이트명 VS 문서제목 을 크롤러수집 VS rss정보수집 으로 판단할 수 있는 근거는
실제 XE사이트들은 rss발행에서는 문서제목만 제공합니다.
그리고 사이트를 직접 방문했을 경우는 통상적으로 문서제목 - 브라우저타이틀 - 사이트명 으로 보이게 설정합니다.
만약 브라우저에서 보일때 위와 같은 형식이 아닌 다른 형식으로 설정했다면 봇이 긁어가서 교체할때 지금 예시와 다른 모습으로 보여집니다.
어쩐지 문서 제목이 바뀐다했더니.. 좋은 정보 감사합니다