작년 연말 즈음 부터 발생한 문제로 XE타운도 그렇고 저희 사이트도 그렇고 글 내용이 아닌 부분들이 글 요약을 색인되는 문제가 있어 제가 몇번 게시글을 작성했으나 특별한 답을 찾지 못했습니다.
네이버는 원래 그래 멍청해 그러니 신경쓸 문제가 아니야 라고 생각하신다면 뒤로가기를 눌러주세요.
저는 문제가 있다면 원인이 있고 해결할 수 있다면 꼭 해결을 해 보려는 생각을 가지고 문제를 다루곤 합니다.

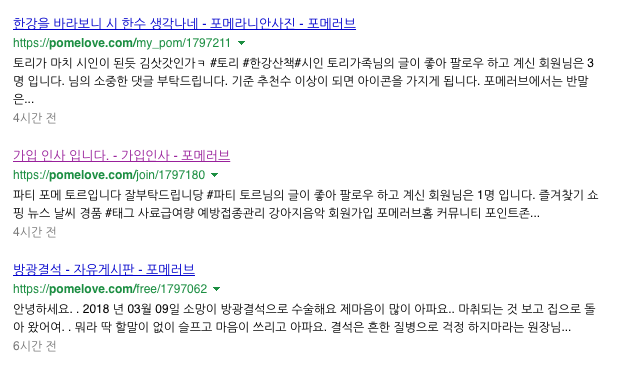
네이버 검색창에 site:도메인 으로 검색했을때 해당 도메인이 가지고 있는 웹문서가 어느정도인지 보여주는 결과입니다. 이 검색에서 바로 문제가 발생되고 있다는 점 입니다. 그런데 모르셔서 그렇지 굉장히 많은 대다수의 사이트가 정도의 차이만 있을뿐 동일한 문제를 가지고 있습니다.
저희는 좀 심한게 보시면 회원의 정보와 게시글복사해가는 주소가 표시되고 글 내용은 아예 없습니다.

바로 동그라미친 부분을 글 요약으로 넣고 그리고 글 내용은 건너 띄고 또 글 아래 내용을 요약을로 색인 했습니다.
저희는 글 내용은 1도 없습니다. 만약 저대로 검색자에게 노출이 된다면 낭패가 되겠지요.
그러나 너무 큰 걱정은 안하셔도 됩니다. 제가 확인해 보니 키워드로 매칭되는 검색결과에서는 정확하게 글 내용이 색인된 것으로 노출이 됩니다. 동일한 문서여도 site:도메인 방식으로 검색할 때 문제가 생기는 상황입니다.
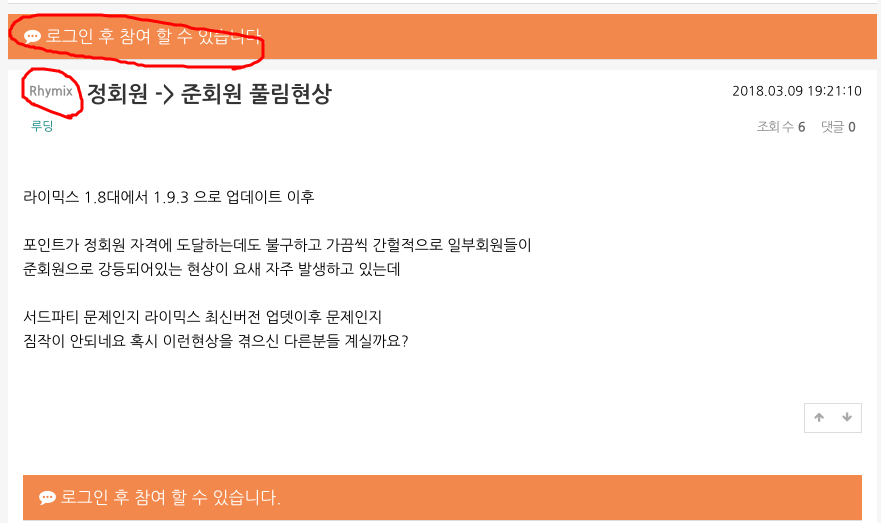
xe타운의 글 하나를 볼까요 ??

동그라미 친 부분이 글과 관련없는 부분이 색인이 되었습니다. 저건 뭘까요? 놀라지 마세요. 레이아웃 메뉴에 있는 묻고답하기가 속해있는 메뉴들입니다. 그부분이 글 요약을 수집이 된 것입니다.
그래도 XE타운은 저희보다 조금 나은게 글 내용이 1보다 많은 양이 있습니다. ㅋㅋ
저는 처음에 rss내용 또는 소스의 meta를 왜 못가져가고 저렇게 엉뚱한 것을 가져가지 라는 접근만 했습니다. 그러다 보니 문제의 원인에 접근하지 못하고 있었습니다.
그런데 어느 순간 이게 파싱을 해서 그 안의 명확한 meta 소스만을 참조하는게 아니구나 라는 것을 눈치챘습니다. 왜 이리 오래걸렸을까요.. 그걸 의심하는데..
분명 보드스킨,레이아웃 등 엉뚱한 부분이 글 내용으로 수집되는 것을 고민하고 있어 놓구서 말입니다.
이 문제 해결을 위해 @기진곰 님과 함께 또는 필요하다면 의뢰를 통해 해결해 보기 위해 대화를 나누었습니다. 저는 파싱해서 문서를 가져가 그 가져간 내용 중에 글 요약을 찾아내는 방식 이라는 것 까지 생각을 했고 서버의 세팅 문제가 있을 것이라는 추측으로 대화를 했는데 기진곰님의 의견은 시멘틱한 구조의 문제일 것이라는 의견을 내셨습니다.
저도 서버세팅의 의심은 접고 그럼 네이버의 검색봇이 파싱을 하면서 오류를 일으킬 수 있다는 것에 촛점을 맞추고 테스트해 나가기로 했습니다.
사실 엇그제 @BNU 님과 함께 템플릿에서 문법이 먹히지 않는 문제를 해결하는 과정에서 사소한 문법적인 오류로 파싱하는 것에 오류를 유발할 수 있다는 것을 확인했습니다.
그러던 중 기진곰님께서 저희 글 내용이 나오는 곳과 가까운 윗쪽의 사소한 오류를 발견해 주셨습니다.
해당 오류를 제거하면서 저희 문서의 요약으로 잘못 가져가는 부분인 회원의정보,글복사 부분을 크롤러는 제한하는 조건을 걸어 검색엔진이 해당부분이 없는 것 처럼 만들어 주었습니다.
이렇게 처리한 이유는 기진곰님과 대화를 하면서 어느정도 내린 결론이 네이버에서는 h1태그(글제목)을 찾고 그 아래에서 내용을 찾는 것이라는 추측성 결론을 내리게 되었습니다.
깔끔해졌죠??
네, 물론 site:도메인 으로 검색했을때만 문제가 됩니다. 궁금한 것을 단어로 검색했을때는 제대로 된 것으로 제공하고 있습니다. 그러니 만약 내 사이트도 도메인명으로 검색했을때 엉망이라도 그냥 두셔도 됩니다.
그런데 사실 이 검색결과가 웹마스터도구의 색인을 의미합니다. 네이버 내부적으로는 이 자료를 이용할 가능성이 매우 높습니다. 사이트를 평가한다던지 문서를 평가한다던지...
문서는 다른데 같은 내용이 반복이 된다거나 한다면 나쁜 평가를 받겠죠. 그리고 찜찜하니까 저는 고치고 싶었습니다.
네이버도 파싱을하면서 meta 소스에 있는 글 요약으로 색인을 합니다.
그리고 지금 언급한 방식으로도 글 요약을 색인을 합니다.
사이트 문서를 읽어가서 봇이 글 내용을 찾아내는 방식에 대응을 하고 싶다면 지금 제가 제안하는 것을 하셔야 합니다.
1.글읽는 스킨에 저 처럼 불필요한 것을 넣었다면 특히 글 제목 또는 내용 부근에 넣으셨다면 제거하시는게 좋습니다. 제거하기 싫다면 봇이 접근하지 못하도록 조건을 걸어주셔야 합니다.
2.게시판 목록에서 게시판의 안내나 공지를 위해 넣으신 부분도 가급적 글 읽는 곳에서는 나오지 않도록 하시는게 좋습니다.
1,2번의 이유는 언급한 부분들 중 사소한 문법오류가 있거나 혹은 봇이 해석하기에 혼돈을 주는 것들이 있다면 봇이 파싱을 하면서 글 내용부분을 엉뚱한 곳으로 찾게 됩니다.
XE타운은 h1 태그에 인접한 카테고리를 출력하는 부분 그리고 로그인유도하는 부분의 코드가 어느정도 방해를 하고 있는 듯 합니다. 그래서 엉뚱한 레이아웃의 메뉴 부분을 가져오고 있습니다.
길게 적었지만 결론을 한줄로 적으면
제목 부근에 문법오류 또는 복잡한 코드를 넣지 마시고 만약 꼭 유지해야 한다면 !isCrawler() 로 봇에게는 가려주세요.
그럼 내용을 못찾던 봇이 잘 찾게 되는 결과를 보실 수도 있습니다. 저희 처럼요....
사실 네이버의 수집 방식에 관해 좀더 자세한 설명이 필요하지만 일부 생략을 한 부분이 있습니다. 핵심만 설명해 드리려다보니 다소 이해가 안가는 부분도 있을 겁니다.


