게시글이 10만개가 넘으니 게시글 검색이 느려지는게 체감이 점점 오더니 결국엔 엘라스틱서치를 자체적으로 적용(개발)하게 되었습니다.
엘라스틱서치를 이번 기회에 처음 만지게 되었는데, NoSQL을 이렇게 본격적으로 만져본 적은 처음이기도 하고 해서 생각보다 많이 낮설었습니다.
처음엔 형태소 분리에서 헤메다가 계속 삽질을 하다보니 해결하였으나... 여러모로 넘여야 할 산들이 많더군요 ㅋㅋㅋ
elasticsearch가 NoSQL이다보니 기존 RDBMS의 서브쿼리, join같은 기능을 사용하지 못하는 점이 젤 힘들었습니다.
특히 제일 문제가 되었던 점은
- 댓글, 확장변수 검색 상태에서 게시글 정렬시 voted_count, blamed_count, readed_count, comment_count 등.. 기준으로 정렬
문제였습니다.
기존 mysql에선 그냥 join한 다음에 group by 하면 쉽게 해결될 문제지만 엘라스틱 서치에선 이런 기능을 지원하지 않으니 기존 데이터를 비정규화 작업을 한 다음에 elasticsearch 작업에 넣는 작업이....정말 만만찮은 작업이더라구요.
정상적인 방식에선 적어도 2~3개의 인덱스(mysql에선 테이블. mysql의 인덱스와는 다른 개념입니다.)를 참조해야 하나, elasticsearch의 구조적인 특징때문에 한개의 인덱스만 참조가능하다보니 한개의 인덱스로 게시글 목록을 가져오는 작업이 어려웠습니다.
제목+내용, 제목, 내용 검색같은 경우 어려운 문제는 아니지만
'댓글, 확장변수로 검색할 경우 게시글 정렬순서는 어떻게 가져오는가??' 가 어렵긴 하더라구요.
구글검색을 열심히 하니 댓글은 nested라고 해서 게시글 데이터에 포함하는 방법을 사용하신 분이 있는데 실제로 적용해보니 성능상의 문제로 패스..(제가 잘못 시도해서 성능이 안좋았을수도 있지만요 ㅎㅎ)
그래서 comment index에다가 게시글의 "title", "voted_count", "blamed_count", "readed_count", "comment_count", "regdate" 등과 같은 데이터들을 같이 저장하면 어떨까? 라는 생각이 들었습니다.
문제는 게시글의 정보가 바뀔때마다 comment의 데이터도 함께 변경해줘야 한다는 문제점이 있었습니다.
게시글에 댓글이 1000개가 있는 상태에서 게시글의 제목이 바뀌면 게시글(1개) + 기존 댓글에 비정규화된 데이터(1000개)를 수정해야 한다는 문제가 발생합니다.(nested방식을 사용했을때도 내부적으로는 이렇게 돌아가지만요)
기본적으로 elasticsearch와 같은 nosql은 update, delete 작업이 느려서 자주 업데이트 시키고 싶지는 않았습니다.
특히 조회수가 업데이트되는 일은 매우 빈번하게 발생되고, 이런일이 발생할때마다 elasticsearch에 있는 데이터들을 업데이트 하기엔 매우 비효율적인것 같더라구요.
굳이 업데이트를 해야한다면 별도의 집계서버를 놔두고 이벤트 소싱(https://mjspring.medium.com/%EC%9D%B4%EB%B2%A4%ED%8A%B8-%EC%86%8C%EC%8B%B1-event-sourcing-%EA%B0%9C%EB%85%90-50029f50f78c)을 사용하여 주기적으로 elasticsearch의 값들을 갱신해줄수는 있지만 '굳이..??' 라는 생각에 패스.
위의 문제를 종합해보면
- 비정규화를 사용해야한다 (댓글 데이터에 게시글 데이터도 함께 저장)
- 게시글의 데이터가 업데이트 될때마다 관련있는 비정규화된 데이터들도 함께 업데이트를 해야한다
- 하지만 elasticsearch의 비정규화된 데이터를 매번 업데이트하는것은 매우 비효율적이다
- 그렇다고 elasticsearch서버의 직접적인 잦은 업데이트를 방지하기 위해 별도의 집계서버를 쓰기는 싫다
어떻게 이 난제를 해결할 것인가.. 참 고민이 많이 되더라구요.
결국엔 댓글 데이터엔 게시글의 "list_order", "user_id", "regdate", "member_srl"만 함께 저장하기로 했습니다.
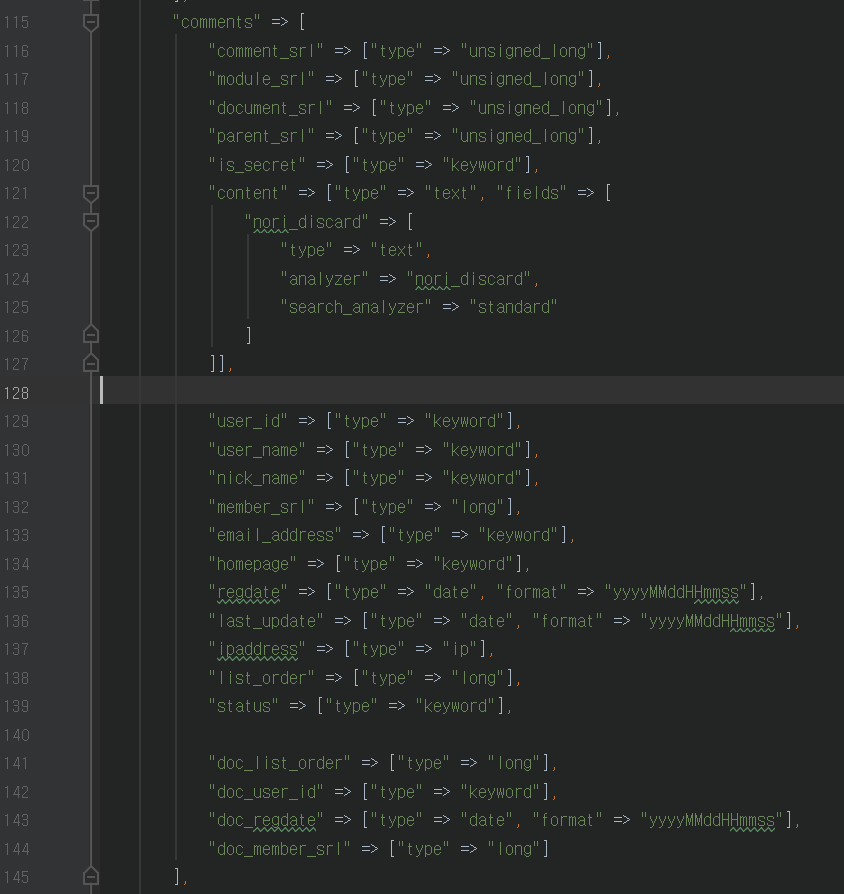
실제로 "regdate", "list_order"순 정렬을 많이 사용하는걸 생각한다면
"readed_count", "voted_count", "blamed_count", "comment_count", "last_update", "update_order"를 사용할 일이 없을것이니까요.
무엇보다도 상기 언급된 컬럼들이 업데이트가 제일 빈번하게 일어나기도 하여서 과감하게 뺐습니다.
댓글 뿐만 아니라 확장변수의 index도 동일하구요.
이렇게 수십번의 인덱스 생성, 삭제와 매핑작업을 진행하다보니 문득 드는 생각이
elasticsearch의 빠른 속도를 유지함과 동시에 xe의 모든 기능을 사용한다는 것은 어려운 것 같습니다. ㅠㅠ
이론적으로 불가능한건 아니지만 노력에 비해 별로 쓰지도 않는 기능을 구현하기는..ㅎㅎ(물론 저만 쓰지 않는 기능일 수도 있습니다..)
하여간 이렇게 비정규화 작업이라는 큰 산을 넘으니 이번엔 타임라인 모듈 연동이라는 또 다른 산이 보이는군요 ㅋㅋㅋ
물론 이후엔 최적화라는 더 큰 산이 있겠지만요..
이렇게 작업을 하고 테스트로 게시글 검색을 수행하니 확실히 mysql의 like검색에 비해 훨씬 빠르네요. ㅎㅎ
노력한 보람이 나오는것 같습니다. (감격)
나중에 개발이 끝난다면 후기한번 작성하겠습니다!

