nginx 서버에서 운영중인 사이트에서 과다하게 접속하는 ip 대역을 발견하고 차단을 하려고 시도 중입니다.
https://erulabo.com/post/deny-specific-ip-on-nginx
저는 위 팁에서 특정 ip 대역 전체 ( ex: 185.191.171로 시작하는 전체 아이피 )를 적용하려고 합니다.
CDR 계산기 ( https://www.ipaddressguide.com/cidr )에서 나온 아래 값 모두를 넣어주는게 맞는건지 문의드립니다.
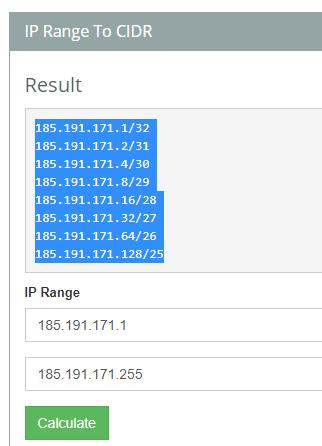
[ 질문2 ]
185.191.171.3 - - [09/Nov/2020:09:31:00 +0900] "GET /faq HTTP/1.1" 200 7383 "-" "Mozilla/5.0 (compatible; SemrushBot/6~bl; +http://www.semrush.com/bot.html)" "-"
185.191.171.3 - - [09/Nov/2020:09:31:00 +0900] "GET /faq HTTP/1.1" 200 7383 "-" "Mozilla/5.0 (compatible; SemrushBot/6~bl; +http://www.semrush.com/bot.html)"
185.191.171.### 으로 시작하는 위 봇이 어떤 봇인지 혹시 아시는 분 계신까요?




1부터 시작하시는 바람에 결과가 복잡하게 나왔네요.
0부터 시작하면 아주 간단하게 185.191.171.0/24 라고 나올 겁니다.
다른 대역도 마찬가지로, 맨 뒷자리를 0으로 바꾸고 /24를 붙이기만 하면 됩니다.
이걸 통째로 넣으시면 됩니다.
conf.d 폴더의 파일들은 대부분 자동으로 로딩되니 include 명령을 따로 써주실 필요가 없을 것입니다.
(자동으로 로딩되는데 또 include하면 중복로딩 오류가 발생할 수 있습니다.)